從排名到評分
我們在 Meilisearch 中為搜尋結果新增相關性分數的歷程。

歡迎來到文字自助餐!點餐吧,我們會為您送上 20 篇最精選的文件,這些文件最符合您的查詢!好吧,我們說精選,但我們不會確切地告訴您它們與您的查詢匹配的程度,我們只保證它們是我們擁有的最好的。您說,無法接受嗎?您是該地區最著名的餐廳評論家,您需要能夠區分完美匹配和文字沙拉,是嗎?哦,那聽起來確實很麻煩…

Meilisearch 是一個開放原始碼的搜尋引擎,旨在提供快速、高度相關的搜尋,且整合難度低。它能夠將文件儲存在稱為索引的群組中,並搜尋這些索引以擷取與每個查詢相關的文件。順帶一提,如果您想讓生活更輕鬆,並專注於您提供的搜尋體驗,我們提供雲端解決方案,該解決方案始終受益於我們的最新版本 😉
在最近的 [1.3 版本發布](/blog/v1-3-release/) 之前,Meilisearch 無法得知文件與特定搜尋查詢的匹配程度。本文深入探討了促使我們新增此功能的歷程。
動機
為文件提供相關性分數有助於許多廣受要求的用例
- 根據文件的分數調整搜尋結果的呈現方式。例如,開發人員 bakerfugu 有一個 日曆應用程式,並且想要使用顏色區分來突顯會議和活動的相關性。然而,搜尋結果的順序不足夠,因為即使是頂部的結果,相關性也可能會有所不同。如果沒有分數,我們只知道它是 Meilisearch 所能找到的最好的結果。
- 實作彙總搜尋。彙總搜尋是一種顯示來自搜尋多個索引的結果的方式,就好像搜尋是針對單一統一索引執行的一樣。使用者在 各種 GitHub 討論中報告了真實世界的用例。
- 實作分片。分片類似於聯邦式搜尋,它會組合多個搜尋查詢的結果。與聯邦式搜尋不同,分片涉及查詢多個 Meilisearch 實例上的分割索引,而不是查詢同一實例中的多個索引。預計資料會更同質,但必須在查詢完成後進行重新排名,可以說是「離線」進行。
- 理解相關性。Meilisearch 使用一組預先定義的規則來排名文件。透過產生每個排名規則的詳細分數,可以更深入了解個別規則如何應用於特定查詢的文件。這有助於發現在每個用例中最大化相關性的最佳設定。
從這四個用例中,我們可以看到實作評分功能的設計空間很大。解決方案應該展現哪些屬性,才能最佳地解決所有這些用例?讓我們來看看它們。
目標屬性
從不同的用例中,我們可以看到多個不同的使用者群體和使用方式。 我們確定了可以提供多個解決方案的兩個軸線
- 彙總分數與詳細分數。對於日曆用例,每個文件單一的「彙總」分數就足夠了,而為了理解相關性,則需要每個排名規則的詳細分數。理想的解決方案應同時提供彙總分數和詳細分數。
- 機器可讀與人類可讀。大多數用例需要可以由整合或前端自動消化吸收的資訊。但是,如果我們的目標是讓相關性更容易理解,則需要提供人類可讀的資訊。因此,解決方案應在這兩個屬性之間取得適當的平衡。
此外,為了啟用彙總搜尋和分片,分數必須獨立於搜尋索引中包含的文件。實際上,如果將文件新增至索引會變更其他文件的分數,則將該分數與包含不同文件的另一個索引進行比較是沒有意義的。
最後,我們希望評分系統是直觀的:Meilisearch 應該按照相關性分數遞減的順序傳回文件,遵循最少驚奇原則。
特別是最後一個屬性,使我們傾向於採用基於 Meilisearch 已執行的排名的解決方案,以此作為保證排名和評分之間一致性的手段。
總而言之,解決廣泛的用例需要一個評分功能,該功能不僅提供彙總和詳細分數,還能滿足機器和人類可讀性。它還應保持分數獨立性,無論搜尋索引中的文件為何,並且與 Meilisearch 現有的排名系統對齊。若要了解我們如何根據排名來建構此評分系統,我們首先需要了解排名本身。
遞迴桶排序
本節介紹 Meilisearch 如何根據搜尋查詢對文件進行排名。如果您已經知道 Meilisearch 使用的遞迴桶排序演算法,請隨意跳過本節。此外,由於本節著重於搜尋演算法,因此未涵蓋引擎的其他部分,例如索引編製。如果您有興趣了解更多關於這些的資訊,我們之前在 [專門的文章](/blog/how-full-text-search-engines-work/) 中介紹過它們。
Meilisearch 的核心是使用一種稱為「桶排序」的演算法。它根據一組排名規則將文件排序到不同的桶中。第一個排名規則適用於所有文件,而每個後續規則僅作為決賽平手者使用,以排序在桶內被視為相等的文件。當所有「最內層」的桶都包含單一文件,或在應用最後一個排名規則後,排序完成。
例如,words 排名規則會根據文件中找到的查詢字詞數量對文件進行排序。如果多個文件最終進入同一個桶中,則會使用另一個排名規則(如 typo)來區分它們。
對於查詢「Badman dark knight returns」,words 排名規則會將傳回的文件排序到 4 個桶中,從包含所有字詞(可能包含錯字)的文件到僅包含「Badman」的文件。typo 排名規則有助於我們進一步區分最後一個桶中的文件。
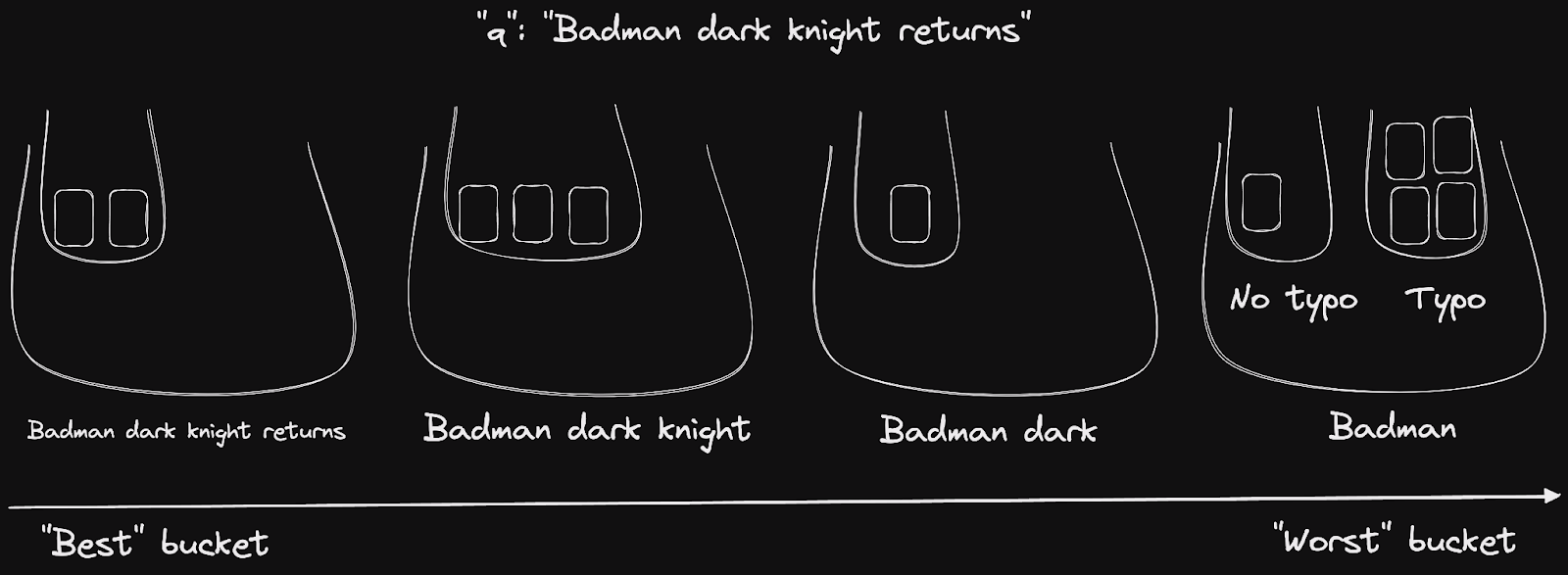
👉 請注意,此規則對其他三個桶沒有影響,因為它們只包含查詢有錯字「Badman -> Batman」的文件。
現在我們對 Meilisearch 排名文件的方式有很好的理解,讓我們回顧一下我們對評分功能的期望屬性
- 它應同時提供彙總分數和詳細分數
- 它應滿足機器和人類可讀性
- 它應保持分數獨立性,無論搜尋索引中的文件為何
- 它應與 Meilisearch 現有的排名系統對齊。
我們如何擴展 Meilisearch 的排名行為來產生符合這些標準的分數?接下來我們將探討這個問題。
從排序到評分
根據我們剛剛學到的知識,每個排名規則都會將整個資料集分成幾個桶,然後依序傳回它們。然後,我們可以利用每個桶的排名和每個規則的桶總數來計算分數,從而產生遞迴桶評分演算法。

讓我們重用我們的主導「badman」範例來付諸實踐。我們計算出 words 桶的數量為 4 個,以及每個桶的內部 typo 桶的數量。我們得出下圖所示的結果。
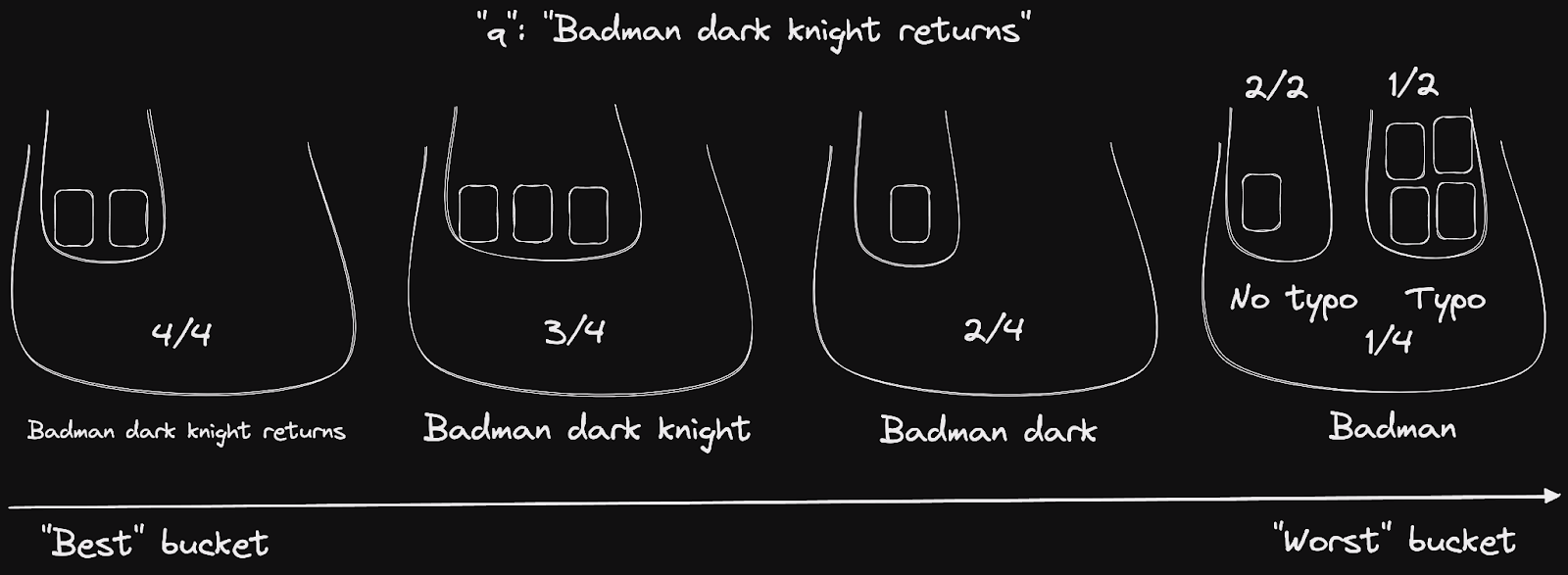
以分數標示的文件桶
透過將遞迴桶排序應用於我們對範例 movies.json 資料集的查詢,我們得到以下排名。為簡單起見,我們已將資料集設定為只有標題是可搜尋的屬性,這使得結果更容易掌握。透過這樣做,我們可以為每個文件指定一個由兩個部分組成的詳細分數,得出以下結果
| 字詞與錯字分數 | 電影標題 |
|---|---|
words 4/4,typo 1/1 | - 蝙蝠俠:黑暗騎士歸來,第一部 |
| - 蝙蝠俠:黑暗騎士歸來,第二部 | |
words 3/4, typo 1/1 | - 蝙蝠俠的真實面貌:黑暗騎士的心理學 |
| - 黑暗騎士傳奇:蝙蝠俠的歷史 | |
words 1/4,typo 2/2 | - 天使與惡棍 (Angel and the Badman) |
words 1/4,typo 1/2 | - 蝙蝠俠:元年 (Batman: Year One) |
| - 蝙蝠俠:紅帽之下 (Batman: Under the Red Hood) |
這為我們的每個排名規則提供了一個初步的形狀、詳細的分數,儘管我們可能希望使用特定於規則的語義資訊來增強分數,例如匹配的單字數量和錯字的數量。
我們尚未探討如何從這些詳細的分數中為每個文件生成單一分數,如何確保其與資料集的獨立性,以及如何處理排序規則的特殊情況。
那麼,我們如何從這些適用於進階使用案例的複雜分數,轉變為每個文件的單一彙總分數,以用於不需要如此高詳細程度的使用案例?我們將在下一節中討論。
彙總分數
為了保持評分系統的直觀性,彙總分數必須與 Meilisearch 給出的排名一致。請記住,後續的排名規則主要用於解決先前規則中的並列情況。同樣地,後續的排名規則應僅完善從先前規則得出的分數。
考慮到這一點,讓我們修改之前的圖表。與其將 words 儲存區標記為「4/4」表示文件符合所有單字,不如說此儲存區中的文件落在 3/4 到 4/4 的範圍內。我們將讓 typo 排名規則決定它們的確切位置。僅取最後一個 words 儲存區,因為它具有兩個 typo 內部儲存區
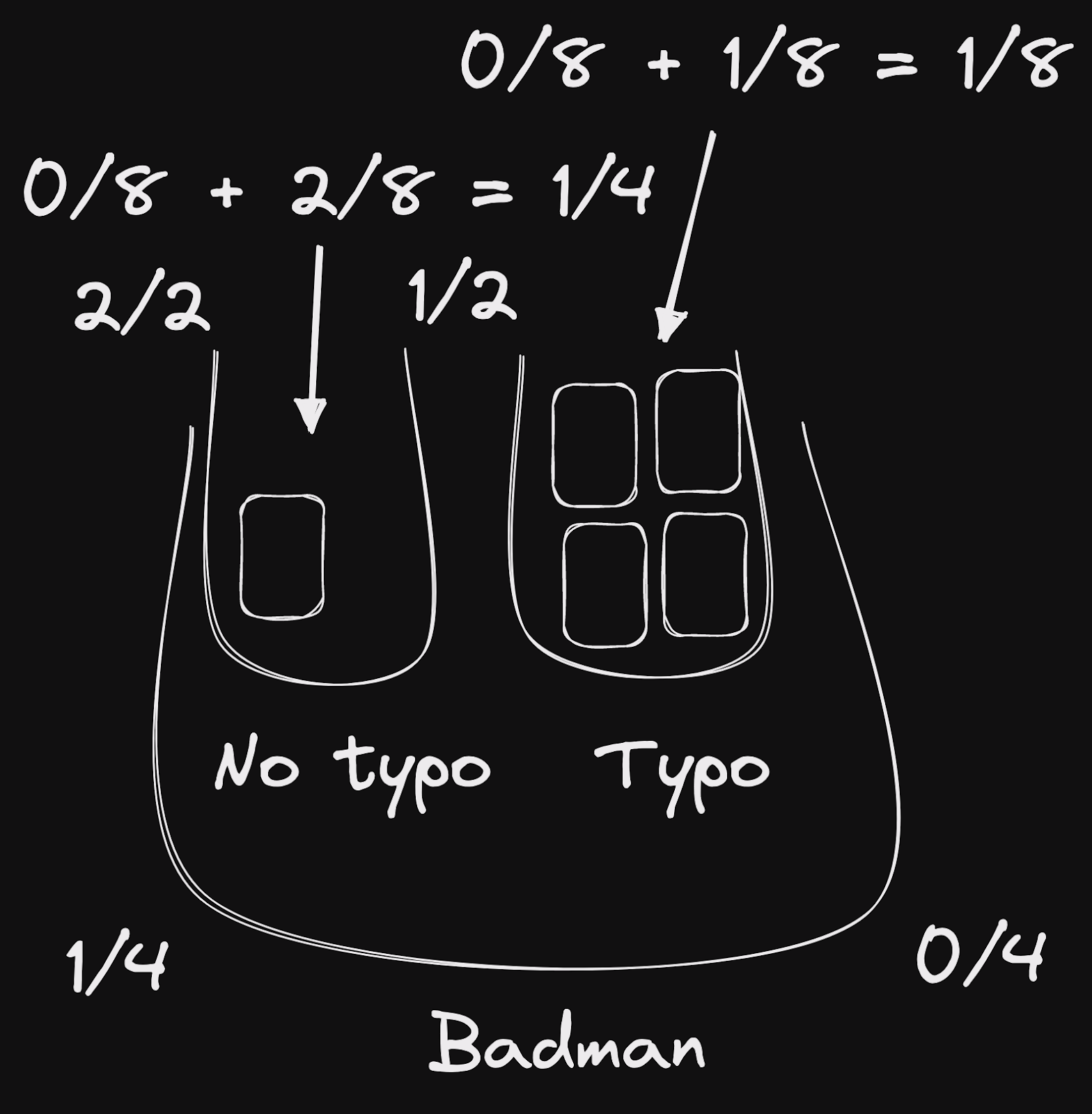
這樣,我們可以計算每個文件的彙總分數
words4/4,typo1/1: 1.0words3/4,typo1/1: 0.75words1/4,typo2/2:0.25words1/4,typo1/2: 0.125

以上提供了分數的直觀概念,但應謹慎處理實施的細節。特別是,我們只為 3 個最佳 words 儲存區放置一個 typo 儲存區,因為**在我們的索引中**,沒有任何文件在這些單字儲存區中沒有「Batman」上的錯字。
現在,如果我們新增一部名為「惡棍重返黑暗騎士」的新電影會發生什麼事?我們現在在第一個 words 儲存區中有兩個 typo 儲存區,「蝙蝠俠:黑暗騎士歸來,第一部」不再是完美匹配:其分數變成 **0.875 而不是 1.0**。我們需要避免這個問題。
實現資料集獨立性
我們的分數應完全獨立於索引中包含的文件。每個規則都應該能夠僅根據查詢計算儲存區的理論最大數量,而不是根據索引中的文件。
對於 typo 規則,這包括將索引錯字容忍設定套用到查詢,並計算最大的錯字數量。預設設定通常允許五個或更多字元的詞語中有 1 個錯字,以及至少九個字元長的詞語最多有 2 個錯字。
有了這些設定,查詢「Badman dark knight returns」最多允許 3 個錯字(「badman」上 1 個,「knight」上 1 個,「returns」上 1 個),總共可能產生 0 到 3 個錯字的 4 個儲存區。這表示「蝙蝠俠:黑暗騎士歸來,第一部」實際上應該得到 **0.9375** 的分數,無論「惡棍重返黑暗騎士」是否是索引中或任何地方存在的電影(修正以上層級列表中的分數留給讀者練習)。
幸運的是,對於大多數排名規則,可以自然地計算出理論上的最大儲存區數量(詳細說明每個排名規則的方式不在本文的範圍之內,但如果您有興趣,我們會接受提問😊)。不幸的是,sort 和 geosort 排名規則是顯著的例外情況。
排序規則不會影響分數
排序規則系列允許按文件其中一個欄位的值排序文件。
這引發了一個問題。如果我們需要規則可以返回的最大儲存區數量,那麼在按產品價格排序時,該數量應該是多少?請記住,該值必須獨立於索引中的文件。
我們在這裡考慮了多種選擇,例如根據數值分佈自動推斷各種儲存區,同時仍允許開發人員在評分時指定儲存區劃分。最終,我們採用了最簡單的選項,它沒有新增任何額外的 API 介面:分數不受排序排名規則的影響。它們的處理方式就像是返回單一儲存區。
此決定會產生一些阻抗不匹配,因為實際上,Meilisearch 在使用排序排名規則時,會按相同數值將文件分組。這表示,如果您的排名規則先按價格升序排序,然後再按錯字區分,您將會得到以下順序
- 價格為 100 美元,沒有錯字的文件
- 價格為 100 美元,有錯字的文件
- 價格為 200 美元,再次沒有錯字的文件
- 價格為 200 美元,有錯字的文件
由於排序排名規則不會影響分數,因此在 (2) 中返回的文件的相關性分數將低於在 (3) 中返回的文件。畢竟,前者有錯字,而後者沒有。這可能會讓使用者感到驚訝,而且這是我們本來希望避免的事情,但找不到實際可行的辦法。
以另一種方式看待問題可能會使其看起來更自然。雖然大多數排名規則按相關性排序文件,但按欄位排序的排名規則按該欄位的值排序文件,而且最終,只能有一個順序。
總而言之,當使用彙總分數對文件進行排名時,任何按欄位排序的排名規則的效果都會在排名中被抵消。當使用詳細分數時,這不是問題,因為詳細分數提供了用於對文件按欄位排序規則進行排序的值,因此開發人員可以在重新排名時將其納入考量。
使用評分 API
Meilisearch v1.3 允許在搜尋請求中指定 showRankingScore 查詢參數,並將該參數設定為 true 會導致將 _rankingScore 浮點數值注入到搜尋返回的文件中。
然後可以擷取每個文件的分數,並例如根據數值選擇不同的表情符號或 CSS 類別。
| 分數 | 表情符號 |
|---|---|
| 0.99 | 👑 |
| 0.95 | 💎 |
| 0.90 | 🏆 |
| ... | ... |
| 0.25 | 🐓 |
我相信開發人員會想出許多使用此分數的方法,比這個可憐的後端工程師的嘗試更有想像力 😳
Meilisearch v1.3 也公開了 _rankingScoreDetails。但是,由於它們新增了大量的 API 介面,因此目前僅在執行階段實驗性旗標之後才會公開。歡迎您提供意見回饋!
結論
實作相關性分數是 Meilisearch 針對具有大型設計空間的複雜功能進行設計流程的一個範例。
它也代表了絕佳的社群互動機會,因為我們發佈了該功能的幾個原型,並從使用者那裡獲得了回饋。我們要特別感謝使用者@LukasKalbertodt,他對原型的絕佳回饋絕對幫助我們改善了解決方案❤️
我們從評分 API 獲得的早期結果非常有前景
- 除錯相關性。Meilisearch v1.3 已經具有相關性改進功能,這些改進功能因為詳細的分數揭示了相關性 問題而變得顯而易見
- 解鎖彙總搜尋。使用彙總分數對來自異質搜尋查詢和索引的文件進行重新排名,解鎖了第一個版本的彙總搜尋。如果使用實驗性功能開關來啟用詳細分數,則可以使用它們以更精細的方式重新排名文件
- 解鎖混合搜尋。相關性分數可以作為實作混合搜尋的一種方法,同時結合我們在 [語義搜尋](/blog/vector-search-announcement/) 方面所做的工作
我們希望您喜歡深入了解評分功能,並且它對您有所幫助。歡迎隨時在我們的Discord 社群中給予我們回饋。
如需更多 Meilisearch 相關資訊,您也可以訂閱我們的電子報、查看我們的路線圖、參與我們的產品討論、從原始碼建置,或在雲端上建立專案。期待您的參與!


Meilisearch 使用 Arroy 的篩選磁碟 ANN 擴展搜尋能力
我們如何使用 Arroy 的篩選磁碟 ANN 實作 Meilisearch 的篩選功能
