您是否以聰明的方式建立索引?
將您的文件加入 Meilisearch 是否需要太長時間?瞭解您可以採取哪些措施來加速索引程序。

如果您剛使用我們的快速入門指南的電影資料集體驗了 Meilisearch,那麼建立資料索引可能只需要幾秒鐘。但是,如果您使用的是較大的資料集,則可能需要更長的時間。在本文中,我們將回顧最佳實務,以幫助您有效率地建立資料索引並加快索引程序。
定義您的需求
Meilisearch 以離散記錄的形式儲存資料,稱為文件,且每個文件都必須有一個唯一的識別碼,即主鍵。文件會群組到稱為索引的集合中。
為了提供「邊輸入邊搜尋」的體驗,Meilisearch 需要以多種方式儲存和組織資料,以便能夠以最有效的方式檢索資料。因此,文件必須經過徹底的處理才能準備好進行搜尋。
Meilisearch 中每個索引約有 20 個資料結構,而建構這些資料結構是索引程序中最耗時的部分。變更索引設定可能會使許多這些資料結構失效,並需要重新建立資料索引。因此,通常最好在新增文件之前定義索引設定。
可搜尋的屬性
預設情況下,加入 Meilisearch 的所有文件欄位都是可搜尋的。但是,在可搜尋屬性中列出的欄位中出現的文字最需要資料結構,確切來說是 11 個。加快索引速度的一個好方法是確保可搜尋屬性清單中的所有屬性都是您真正想要檢查以比對查詢文字的屬性。
例如,假設有一個包含影像 URL 欄位的文件。您可能想向使用者顯示影像,但我懷疑使用者是否有興趣能夠在 URL 中搜尋查詢字詞。請別忘了,並非所有顯示的欄位都需要可搜尋!
在可搜尋屬性清單中指定實際需要的欄位不僅很重要,而且也必須避免在可搜尋欄位中出現無意義、隨機或唯一的值。想像一下,所有資料庫都充斥著「https」、「www」、「com」或「I77lHE」之類的值,這在嘗試尋找特定產品或電影時並不是很有用 😱
說到這個:🤔唯一的值…這是不是讓你想到什麼?💡主鍵!這是另一個您可以從可搜尋屬性清單中安全移除的欄位。
幕後運作
為了更好地理解自訂可搜尋屬性索引設定的重要性,讓我們來看看可搜尋屬性所需的最大資料結構。在我們提到的 11 個資料結構中,有三個需要最長的時間來建立:WORD_DOCIDS、WORD_POSITION_DOCID 和 WORD_PAIR_PROXIMITY_DOCIDS。
為了更好地理解每個資料結構的運作方式,我們將使用以下文件集作為範例
{ "id": 1, "description": "New York City is the most populous city in the USA" }, { "id": 2, "description": "New York was named in honor of the Duke of York" }, { "id": 3, "description": "Tel Aviv is the new most expensive city in the world" }
在 WORD_DOCIDS 中,每個單字都會與包含該單字的文件的主鍵建立關聯
「new」=> [1, 2, 3]「york」=> [1, 2]
在 WORD_POSITION_DOCID 中,索引鍵是單字及其在文件中的位置。與索引鍵相關聯的值是單字佔據相同位置的文件。在上述文件中,id 將是屬性 0,而 description 是屬性 1
new(1,0) => [1, 2]:在文件 1 和 2 中,單字「new」位於屬性 1 的位置 0,這是屬性description的第一個單字new(1, 4) => [3]:在文件 3 中,「new」位於屬性 1 的位置 4
最後,在 WORD_PAIR_PROXIMITY_DOCIDS 中,Meilisearch 會追蹤索引中所有文件中單字對之間的距離。詞彙之間的距離必須在 8 個單字內才會被儲存,因為距離較遠的單字不會被視為同一內容的一部分,因此不相關。
在上述範例文件中,Meilisearch 將儲存以下配對
newyork1 => [1, 2]newcity2 => [1]newcity3 => [3]
附加到單字配對的數字代表它們之間的距離
- 1 表示單字彼此相鄰
- 2 表示它們之間隔著一個單字
- 3 表示它們之間隔著兩個單字
如您所見,每個新單字都代表 Meilisearch 內部資料結構中的額外列。像唯一 ID 或 URL 字串之類的值可能會使資料庫大幅成長,而且很可能是沒有必要的。
微調 Meilisearch 應搜尋的欄位對於縮短索引時間至關重要。它也可以帶來更高的相關性和搜尋速度,因為結果不會受到不相關資料的污染。
可篩選和可排序的屬性
某些欄位不包含任何單字,但可能仍對於幫助使用者找到他們需要的結果至關重要。此類資料可能比一般基於文字的搜尋更適合用於篩選和排序。
可篩選的屬性是可以作為篩選器來細化搜尋結果的屬性。您可以使用它們來限制特定使用者的搜尋結果,或建立分面搜尋介面,讓使用者可以根據自己選擇的條件縮小結果清單。布林類型的值非常適合作為篩選器。
可排序的屬性是可以在搜尋時用於排序的屬性,這可讓使用者決定要先查看哪些文件。數值非常適合用於排序。
根據經驗法則,如果您的資料集包含具有數值和布林欄位值的文件,請花時間評估它們是否可以成為可篩選或可排序的屬性清單的一部分。
排名規則
排名規則負責搜尋結果的相關性。Meilisearch 包含六個內建的排名規則
[ "words", "typo", "proximity", "attribute", "sort", "exactness" ]
您也可以將自訂規則新增至此清單,以進行升冪和降冪排序
[ "words", "typo", "proximity", "attribute", "sort", "exactness", "price:asc" ]
與用於在搜尋時排序的可排序屬性不同,自訂排名規則用於設定預設順序。
如果您需要這種預設排序,最好事先設定。在文件已建立索引後新增規則將觸發重新建立索引,並可能使您感到惱火!
縮小大小並批次處理
僅索引您真正需要的內容。您的資料庫中所有欄位都是必要的嗎?資料集中欄位越少,文件就越小。文件越小,它們的重量就越輕,到達 Meilisearch 的速度就越快,Meilisearch 就能更快地處理它們。
Meilisearch 會將連續的文件新增請求合併成單一批次並一起處理。這顯著加快了索引過程。由於每個批次的最終大小將取決於 Meilisearch 在處理最新的文件新增請求時收到的資料量,因此建議以群組方式發送文件,而不是一次發送一個。
基於同樣的原因,請考慮壓縮您的資料。Meilisearch 支援 br、deflate 和 gzip 壓縮方法。您可以在我們的文件中找到更多資訊。
隨時保持更新並讓我們知道您的情況
使用最新的Meilisearch 穩定版本。新版本通常包含效能改進,可以顯著提高索引速度。
如果您遇到任何索引問題,請回報它們!這對於改進產品至關重要!
不要相信我,相信數據
在建立一些基準時,引擎團隊的軟體工程師 Many 建立了以下圖表。請注意,索引時間高度取決於機器的大小(CPU、RAM)和資料集:對於類似大小的資料集,您可能會獲得不同的結果。
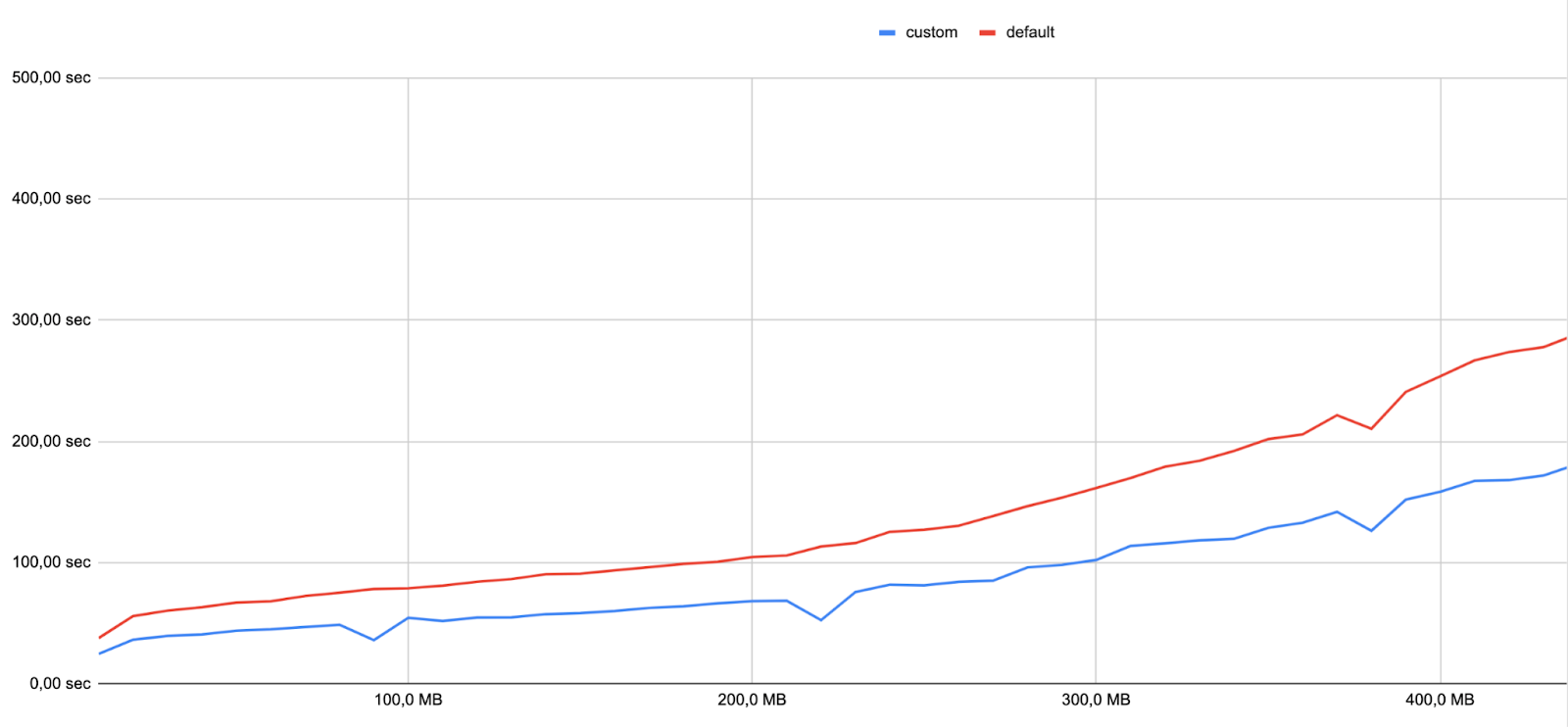
水平軸代表資料集的大小,垂直軸代表索引時間
紅線代表使用預設設定的索引時間,藍線代表使用自訂設定的索引時間。在相同的機器和資料集下,我們觀察到使用自訂設定時,索引速度提高了 36%。
我們觀察到資料庫大小也有類似的改進,使用自訂設定時資料庫大小明顯較小
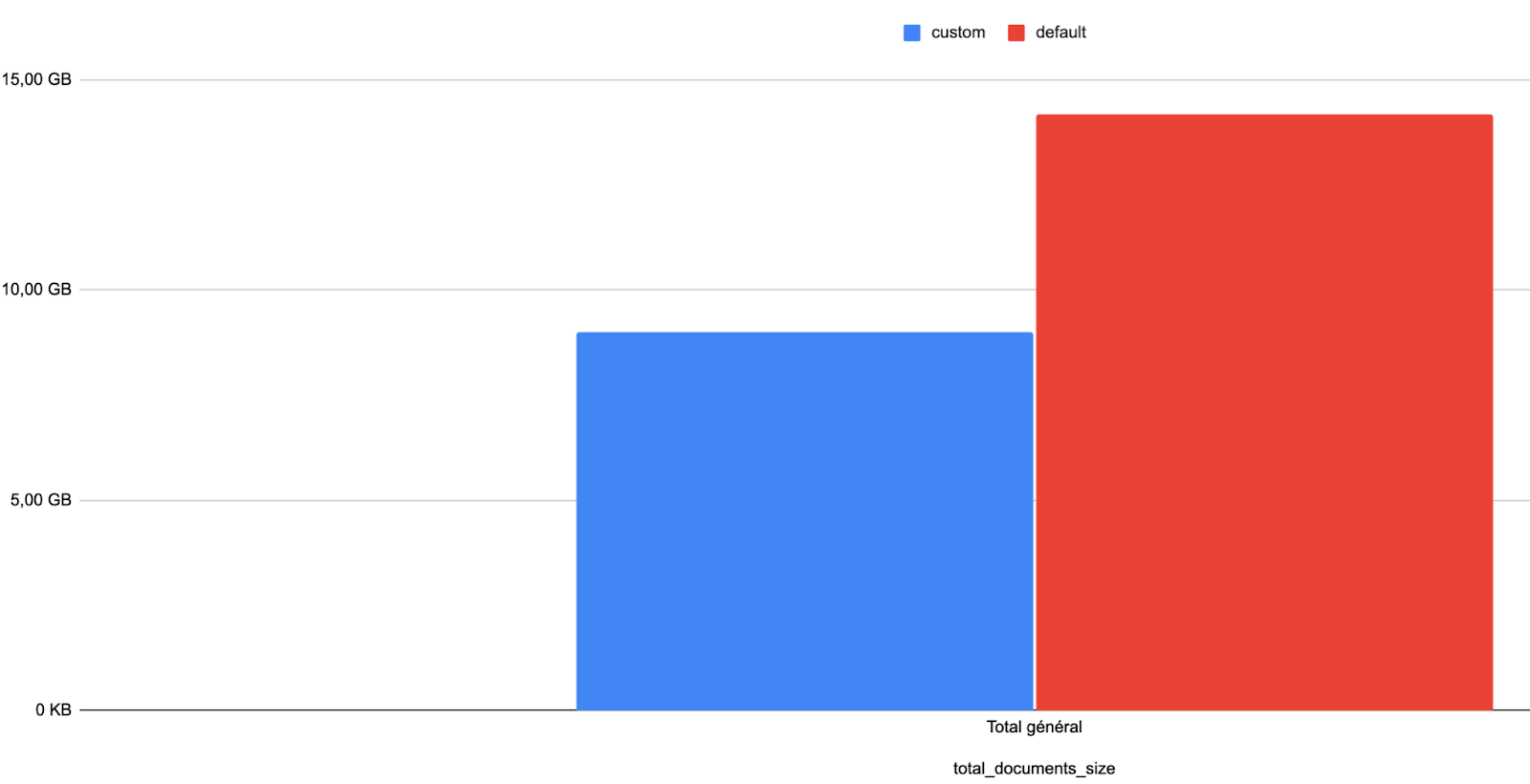
藍色表示使用自訂設定的資料庫大小,紅色表示使用預設設定的資料庫大小
了解更多 Meilisearch 可以為您的業務帶來的價值
這就是目前的所有內容!我們介紹了加速索引過程的最佳實踐。您知道這些技巧嗎?在遵循這些技巧後,您是否注意到索引速度有所不同?在我們的 Discord 上分享您的經驗!
您的回饋是幫助我們改進 Meilisearch 的關鍵!我怎麼強調都不為過,而且我永遠不會厭倦重複這句話,因為這是事實。我們的社群與我們一起建立了 Meilisearch,並持續幫助我們塑造它。
在 GitHub 上提出問題或進行產品討論,查看我們的路線圖,加入我們的Discord 伺服器... 無論在哪裡、無論如何,我們都想聽到您的意見!

如何將人工智慧驅動的搜尋功能添加到 React 應用程式中
使用 Meilisearch 的人工智慧驅動搜尋功能,建立一個 React 電影搜尋和推薦應用程式。

使用 Blazity 建立您的 Next.js Shopify 店面
學習如何使用 Next.js 和 Blazity commerce starter 建立 Shopify 店面。
